Orchestration part 1: Show Me the Receipts: What Machine-to-Machine Fluency Actually Looks Like
A real trace through the stack — Opus Max/Fable(MIA) → Opus (high/medium) → Sonnet. One fuzzy idea, turned into a spec, decomposed into tasks, and shipped — and why the hand-offs are the part that matters.
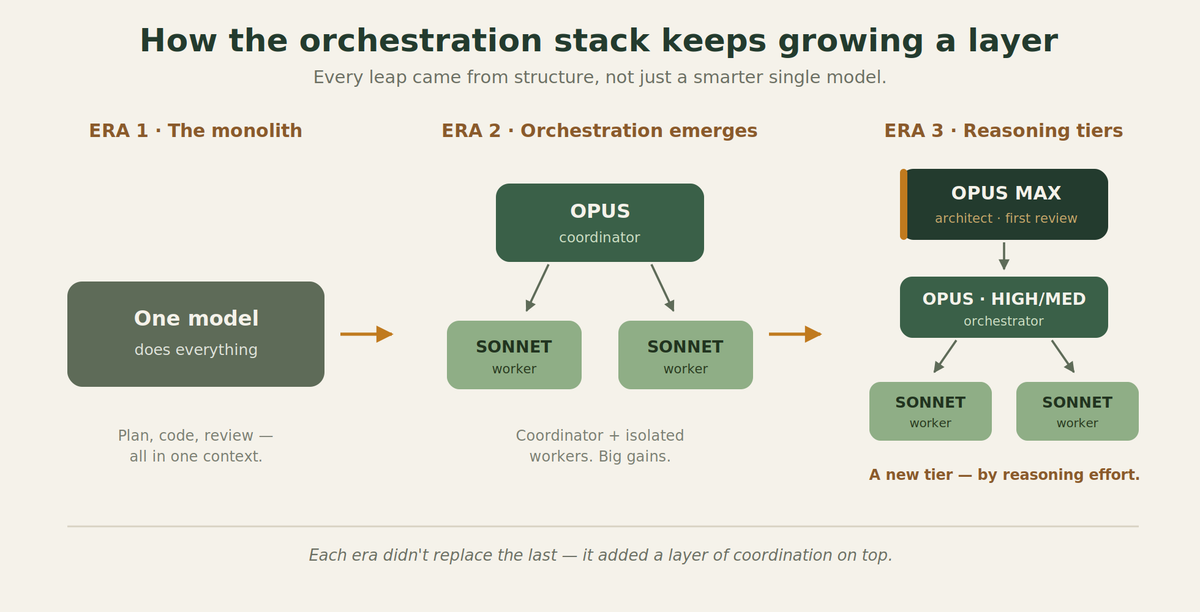
A real trace through the stack — Opus Max/Fable(MIA) → Opus (high/medium) → Sonnet. One fuzzy idea, turned into a spec, decomposed into tasks, and shipped — and why the hand-offs are the part that matters.
In my last post I made a claim: the top of your stack should talk to machines, not to you.
That experiment ran on Fable. With Fable access pulled, I rebuilt the same pattern on Opus reasoning tiers - Opus at maximum reasoning effort as the architect, a lighter Opus as the orchestrator, Sonnet as the workers. The pattern held without a blink, which is the whole point: it was never about a special model. It was about giving each tier something the next one can act on.
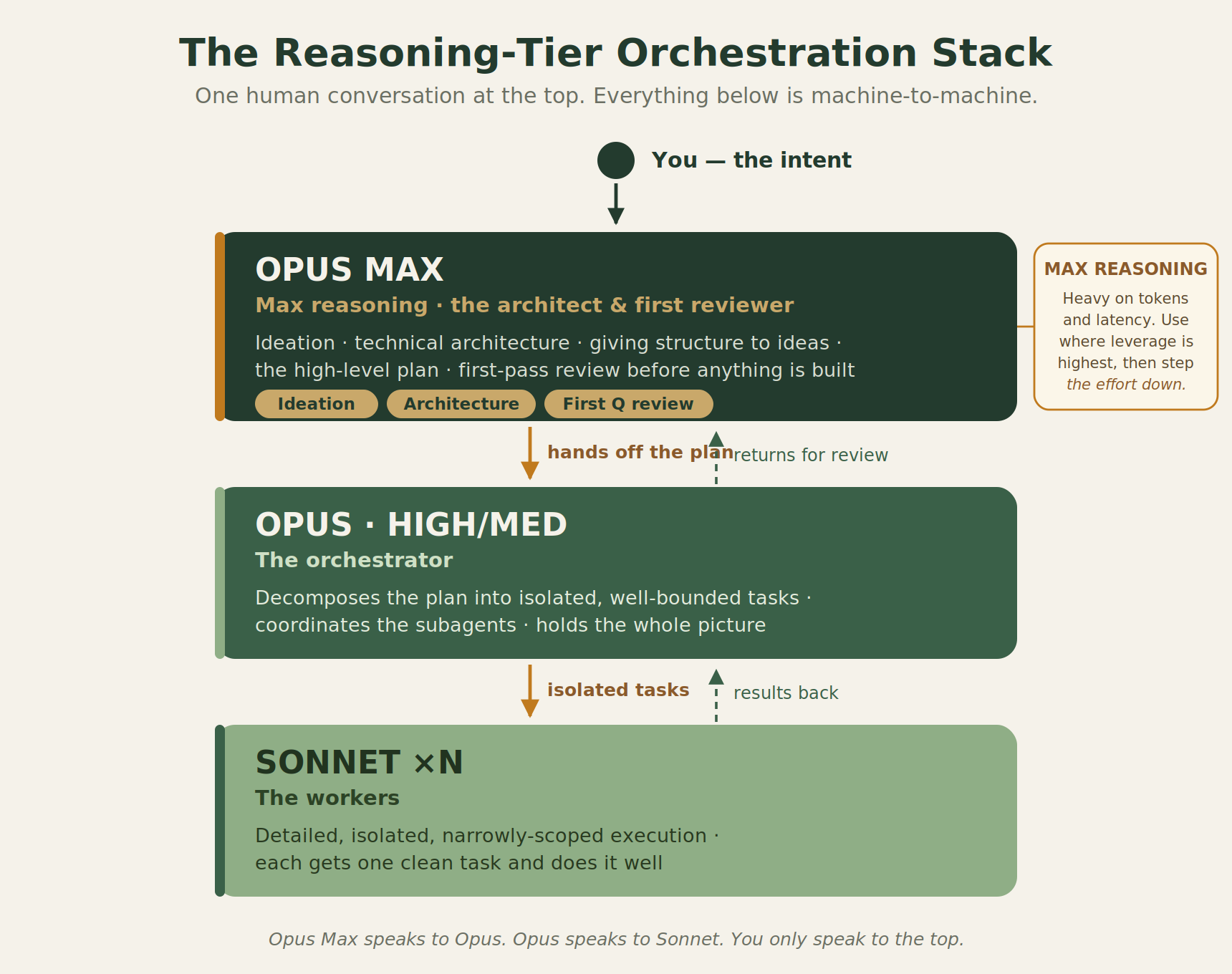
The response to that post was generous, but the sharpest reply was also the fairest one - show me.
So this is the receipts post. One feature, traced from a half-formed thought to working code, with the hand-offs left visible. No benchmark, no theory. Just the artifacts that actually moved between the tiers.
I'll use a real-shaped request from BowSmith — a sight-mark interpolation tool. Archers know their sight marks at a few fixed distances (say 20, 40 and 60 yards) and want the app to predict the mark for anything in between. Simple to ask for. Surprisingly easy to build badly.
A note before you read on: the spec and code below are a representative trace. Where you see […], drop in your own model output and real numbers before publishing. The point isn't my exact artifacts — it's the shape of what travels between tiers.
Stage 0 — The fuzzy intent (human → Opus Max)
Here's what I actually typed. One messy sentence, the way you'd say it out loud:
"I want the app to guess my sight mark for in-between distances from the few marks I've already saved - should feel instant and not lie to me when I'm outside the range I've measured."
That's it. No data model, no edge cases, no opinion on the math. This is the only part of the whole pipeline meant for a human to write. It's vague on purpose.
Stage 1 — The structured spec (Opus Max → Opus orchestrator)
Run at maximum reasoning effort, Opus Max doesn't answer me with a chatty paragraph. It produces something built for the next machine to consume. Condensed:
FEATURE: Sight-mark interpolation
APPROACH: Piecewise-linear interpolation between known marks;
flag (not extrapolate) requests outside measured range.
DATA MODEL: SightMark { distanceYards: Int, markValue: Double }
stored per bow profile, sorted by distance.
EDGE CASES:
- <2 marks saved → feature unavailable, explain why
- distance below min or above max → return result + "estimated, unverified" flag
- duplicate distances → use most recent
ACCEPTANCE CRITERIA:
- exact match on a known distance returns the stored mark
- midpoint returns linear blend, ±0.001 tolerance
- out-of-range never silently extrapolates
QUALITY GATE (first review): unit tests cover all edge cases above;
no force-unwraps; pure function, no UI coupling.Read that as a human and it's a little dry. Read it as the orchestrator and it's a gift: an approach, a data model, the edge cases someone always forgets, and — the part I care about most — a quality gate written up front. That's the first Q in my RPIQ loop, decided before a single line of code exists.
Stage 2 — The task decomposition (Opus orchestrator → Sonnet)
A lighter Opus, at high or medium reasoning, takes that spec and does the thing the orchestration tier is genuinely good at: it breaks the work into isolated, bounded units, each one carrying its own context and its own definition of done.
TASK 1 → worker-A: Add SightMark model + per-profile sorted storage.
DoD: persists, round-trips, deduplicates on distance.
TASK 2 → worker-B: Pure interpolation function (no UI, no storage).
DoD: passes all acceptance-criteria tests from spec.
TASK 3 → worker-C: SwiftUI input view + result display with the
"estimated, unverified" flag styling.
DoD: disabled state when <2 marks; flag visible out-of-range.
TASK 4 → worker-D: Unit test suite mirroring the QUALITY GATE.Notice no worker needs the whole picture. Worker-B never thinks about SwiftUI. Worker-C never thinks about the math. Each one gets a clean, complete, isolated ask — which is exactly the condition under which a fast worker model does its best work.
Stage 3 — The worker output (Sonnet)
Here's worker-B's slice. Small, focused, verifiable:
swift
func interpolatedMark(for distance: Int, from marks: [SightMark]) -> InterpolatedMark {
let sorted = marks.sorted { $0.distanceYards < $1.distanceYards }
guard sorted.count >= 2 else { return .unavailable }
if let exact = sorted.first(where: { $0.distanceYards == distance }) {
return .known(exact.markValue)
}
// […piecewise-linear blend; out-of-range returns .estimated(flagged: true)…]
}The worker never saw my original sentence. It didn't need to. It saw a bounded task with a definition of done, and it produced something the test suite can verify against the gate Opus Max wrote in Stage 1.
The pattern: vague → structured → bounded → verifiable
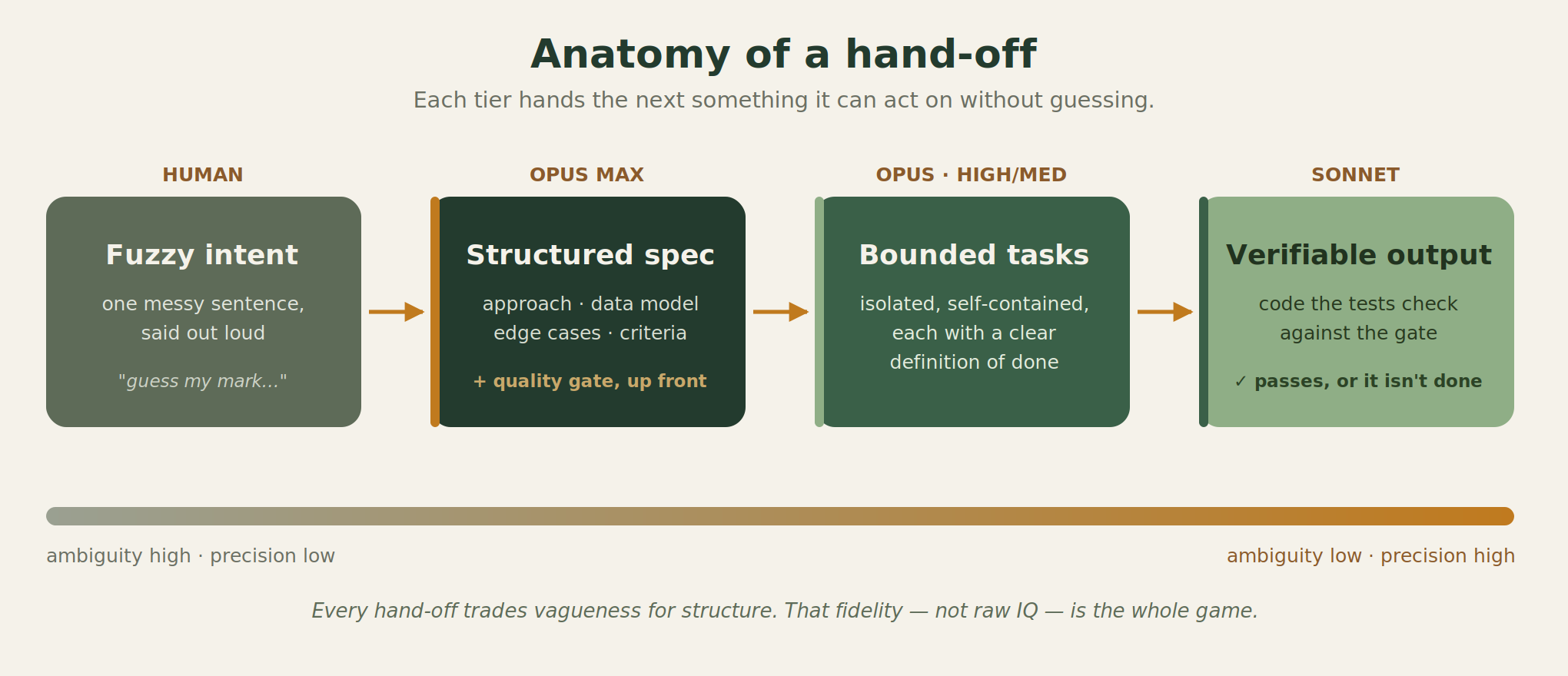
Lay the four stages side by side and the real story isn't any single model's intelligence. It's the fidelity of each hand-off.
A fuzzy intent becomes a structured spec. A structured spec becomes a set of bounded tasks. Bounded tasks become verifiable output. Ambiguity falls at every step; precision rises. Each tier's job is to hand the next one something it can act on without guessing.
That's what "machine-to-machine fluency" means in practice. The top tier's strength isn't charming me — it's writing the Stage 1 artifact so cleanly that the orchestrator never has to interpret intent, and the orchestrator decomposing it so cleanly that the worker never has to ask a question.
Where the bottleneck actually went
For twenty years in quality, the constraint was usually writing the code. In this stack it isn't. The constraint is writing a specification a machine will execute faithfully — and reviewing it before the work fans out. The expensive cognition earns its keep at Stage 1, not Stage 3.
Which is also why I run maximum reasoning only at the front of the loop. Max reasoning is heavy — on tokens and on latency — so I spend it once, on the spec and the gate, and let the lighter orchestrator and the fast workers carry the rest. The receipts make the economics concrete: pay for the architect's thinking deliberately, then step the effort down as the work gets more bounded.
The honest part
This is one trace, lightly cleaned up. Not every feature earns three tiers — a one-line fix doesn't need an architect running at full reasoning, and I'll write about the times the stack was overkill soon. And the proof that matters most is yours, not mine: run your own intent through the tiers and look at the Stage 1 artifact. If it reads like structure for the next machine rather than prose for you, you're seeing the same thing I am.
If you trace one of your own, I'd like to see what your hand-offs looked like — especially where they broke down.
Part 2 of a series on building a coordination layer out of reasoning tiers. Part 1: "The top of your stack should talk to machines, not to you." More on the RPI / RPIQ workflow and the four-surface orchestration model in upcoming posts.


